Stable Diffusion Models: 初学者指南
英文版原文地址(Original address for English language):
原文作者为 安德鲁,以下是他的个人简介:
Andrew 是一位经验丰富的软件工程师,专攻机器学习和人工智能。他对编程、艺术和教育充满热情。他拥有工程学博士学位。
为方便中文用户使用,以下为中文介绍信息,不准确之处请留言我们,我们收到后会及时更新。
稳定扩散模型或检查点模型是预先训练的稳定扩散权重,用于生成特定风格的图像。
模型生成什么样的图像取决于训练图像。如果训练数据中没有猫,模型就无法生成猫的图像。同样,如果只用猫图像训练模型,它只会生成猫。
我们将介绍什么是模型、一些流行的模型以及如何安装、使用和合并它们。
基础模型
基础模型是使用数十亿张不同主题和风格的图像训练的 AI 图像模型。创建这些模型需要投入大量资金和专业知识,而且数量有限。
它们被设计为能够灵活地创作不同的主题和风格。在CivitAI(一个模型共享资源网站)上,几乎所有检查点模型都源自这些基础模型之一。
最受欢迎的基础模型是:
稳定扩散 v1.5
稳定扩散 XL
Flux.1 开发
稳定扩散 v1.5

v1.5 图像。
Stability AI 的合作伙伴 Runway ML 于 2022 年 10 月发布了 Stable Diffusion 1.5。目前尚不清楚它在 1.4 模型上做了哪些改进,但社区很快就将其作为首选基础模型。
Stable Diffusion v1.5 是一个通用模型,默认图像大小为 512×512 像素。
稳定扩散 XL
SDXL 模型是对著名的 v1.5 和被遗忘的 v2 模型的升级。
SDXL 基础模型的改进包括
更高的原始分辨率 – 1024×1024 像素,而 v1.5 版本为 512×512 像素
更高的图像质量(与 v1.5 基础模型相比)
能够生成清晰的文本
很容易创建较暗的图像
Flux.1 开发

Flux AI 模型由黑森林实验室发布,该实验室的许多研究人员都是 Stable Diffusion 1.5 的原始创建者。
Flux AI 基础模型的改进包括:
生成清晰的文本
出色的逼真图像
出色的快速依从性
Flux.1 dev 的默认图像大小为 1024×1024 像素。
微调模型
什么是微调?
微调是机器学习中的一种常见技术。它涉及采用基础模型并在较窄的数据集上对其进行更多训练。
经过微调的模型会生成与训练中使用的图像类似的图像。例如,Anything v3 模型是使用动漫图像进行训练的。因此,它默认会创建动漫风格的图像。
人们为什么要建立稳定扩散模型?
稳定扩散基础模型虽然很棒,但并非面面俱到。例如,它会根据提示中的关键词“动漫”生成动漫风格的图像。然而,创建动漫子类型的图像可能颇具挑战性。与其对提示进行修改,不如使用针对该子类型的图像进行微调的自定义模型。
下面的图像是使用相同的提示和设置但不同的模型生成的。
逼真的视觉:逼真的照片风格。
任何东西 v3:动漫风格。
梦想塑造者:现实主义的绘画风格。

现实愿景

任何东西 v3

梦境塑造者
使用模型是实现特定风格的一种简单方法。
模型是如何创建的?
自定义 检查点模型通过 (1) 额外训练和 (2) Dreambooth 制作而成。它们均基于 Stable Diffusion v1.5、 SDXL或Flux AI等基础模型。
通过使用您感兴趣的附加数据集来训练基础模型,可以实现附加训练。例如,您可以使用额外的老式汽车数据集来训练 Stable Diffusion v1.5,以使汽车的美感偏向老式子类型。
Dreambooth是由 Google 开发的一项技术,可将自定义主题注入文本转图像模型。它只需 3-5 张自定义图像即可运行。您可以拍摄自己的照片,然后使用 Dreambooth 将自己放入模型中。使用 Dreambooth 训练的模型需要使用唯一的关键词来调节模型。
检查点模型并不是唯一的模型类型。我们还有文本反转(也称为嵌入)、LoRA、LyCORIS和超网络。
在本文中,我们将重点讨论检查点模型。
流行的稳定扩散模型
目前有数千个经过微调的稳定扩散模型,并且数量还在不断增加。以下列出了一些可用于通用目的的模型。
现实愿景

基础模型:稳定扩散 1.5
Realistic Vision v5适合生成任何逼真的东西,无论是人物、物体还是场景。
了解有关培养现实人物的更多信息。
梦想塑造者

梦境塑造者模型
基础模型:稳定扩散 1.5
Dreamshaper模型 经过精心调校,打造出一种将照片级写实元素与计算机图形相结合的肖像插画风格。它使用起来非常简单,如果你喜欢这种风格,你一定会喜欢它。
巨无霸 XL
![]()
基础型号:稳定扩散 XL
Juggernaut XL 模型是一款经过精心调优的 SDXL 模型,尤其擅长生成逼真风格的照片。此外,它还使用了多样化的高质量图像进行训练,以创建各种风格。它是 SDXL 基础模型的良好替代品。
小马扩散
基础型号:稳定扩散 XL
Pony Diffusion 是一个 SDXL 模型,使用大量动漫和卡通风格的图像进行训练。它是生成非现实内容的首选模型。该模型极具创造力,并且能够很好地遵循提示。
任何东西 V3

任何 v3 模型。
基础模型:稳定扩散 1.5
Anything V3是一款经过训练的专用模型,用于生成高质量的动漫风格图像。您可以在文本提示中使用danbooru 标签(例如 1girl、white hair)。
它有助于将名人塑造成胺风格,然后可以与说明性元素无缝融合。
一个缺点(至少对我来说)是它会导致雌性体型不成比例。我喜欢用F222来淡化它。
故意 v2

基础模型:稳定扩散 1.5
Deliberate v2是另一个必备模型(太多了!),它可以渲染逼真的插图。效果可能会出乎意料地好。每当你遇到好的提示时,就切换到这个模型,看看会得到什么!
F222

F222
基础模型:稳定扩散 1.5
F222最初被训练用于生成裸体照片,但人们发现它有助于生成具有正确身体部位关系的精美女性肖像。与你想象的相反,它在生成美观的服装方面相当出色。
F222 适合肖像画。它容易产生裸体。在题目中可以添加一些服装相关的词语,例如“连衣裙”和“牛仔裤”。
在这篇文章中寻找更多逼真的照片风格模型。
ChilloutMix

基础模型:稳定扩散 1.5
ChilloutMix 是一款用于生成照片级亚洲女性模型的特殊模型。它类似于 F222 的亚洲版本。与韩语嵌入 ulzzang-6500-v1 配合使用,可以创建韩流女孩。
与 F222 类似,它有时会生成裸照。请在提示中使用“连衣裙”和“牛仔裤”等服装术语,并在否定提示中使用“裸体”来抑制它们。
Protogen v2.2(动漫)

基础模型:稳定扩散 1.5
Protogen v2.2 非常出色。它能生成赏心悦目的插图和动漫风格的图像。
GhostMix

基础模型:稳定扩散 1.5
GhostMix采用 90 年代经典动漫《攻壳机动队》的风格进行训练。您会发现它对于生成半机械人和机器人非常有用。
外福扩散

基础模型:稳定扩散 1.5
Waifu Diffusion 是一种日本动漫风格。
墨水朋克的传播

墨水朋克的扩散
基础模型:稳定扩散 1.5
Inkpunk Diffusion 是一个经过 Dreambooth 训练的模特,具有非常独特的插画风格。
使用关键字:nvinkpunk
寻找更多模型
是下载模型的首选之地。
是另一个很好的来源,尽管该界面不是为稳定扩散模型设计的。
如何安装和使用模型
这些说明适用于 v1 和 SDXL 型号。
要在 AUTOMATIC1111 GUI 中安装模型,请下载检查点模型文件并将其放在以下文件夹中
stable-diffusion-webui/models/Stable-diffusion/按下左上角检查点下拉框旁边的重新加载按钮。
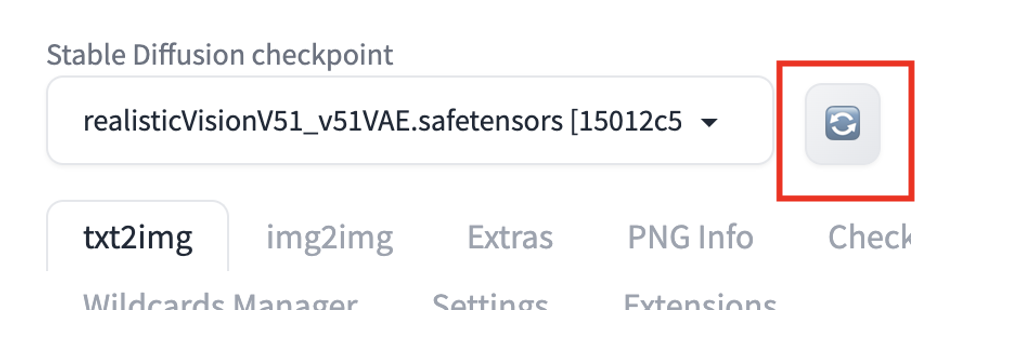
您应该会看到检查点文件可供选择。要使用该模型,请选择新的检查点文件。
或者,选择txt2img 或 img2img 页面上的Checkpoints选项卡并选择一个模型。
如果您是 AUTOMATIC1111 GUI 的新手,快速入门指南中包含的 Colab 笔记本中预装了一些模型 。
跳过片段
某些型号推荐使用不同的“片段跳过”设置。您应该遵循此设置以获得理想的风格。
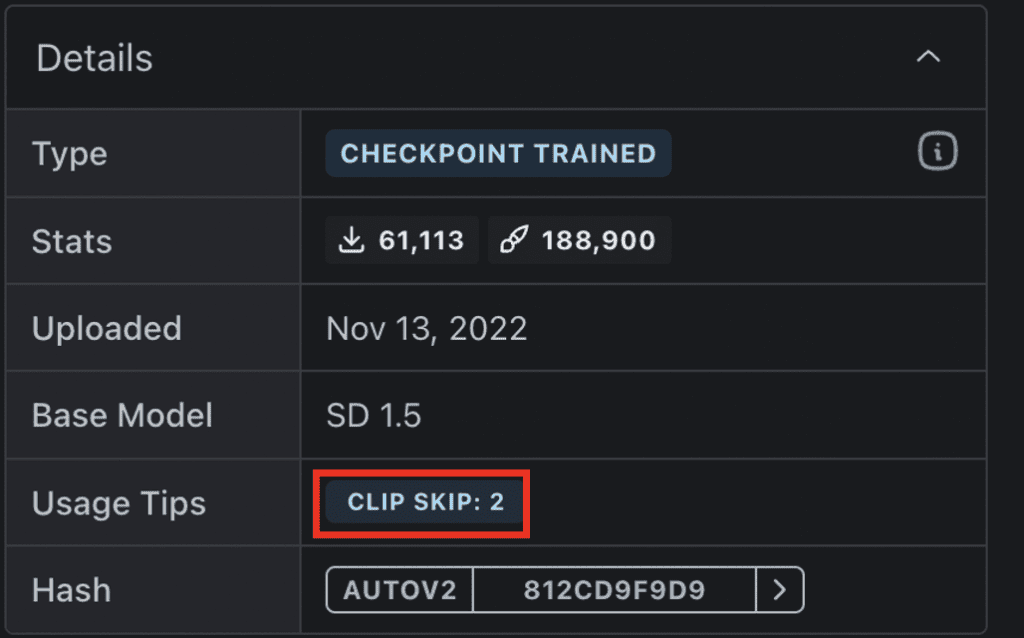
什么是 CLIP Skip?
CLIP Skip是一项功能,可在 Stable Diffusion 的图像生成过程中跳过 CLIP 文本嵌入网络中的多个最后层。CLIP 是 Stable Diffusion v1.5 模型中使用的语言模型。它将提示中的文本标记转换为嵌入。它是一个包含多层的深度神经网络模型。CLIP Skip 指的是需要跳过的最后层数。
在 AUTOMATIC1111 和许多稳定扩散软件中,CLIP Skip 为 1 不会跳过任何层。CLIP Skip 为 2 会跳过最后一层,依此类推。
为什么要跳过一些 CLIP 层?神经网络在层层传递过程中会总结信息。越早的层,包含的信息就越丰富。
跳过 CLIP 层会对图像产生显著影响。许多动漫模型都是使用 CLIP Skip 为 2 进行训练的。请参见下面的示例,其中 CLIP Skip 的设置不同,但提示符和种子相同。

片段跳过 1

片段跳过 2

片段跳过 3
更改任何 v3 的剪辑跳过设置。(剪辑跳过建议为 2。)
在 AUTOMATIC1111 中设置 CLIP Skip
您可以在设置页面 >稳定扩散>片段跳过中设置片段跳过。调整值后,点击应用设置。
但如果你需要定期更改 CLIP Skip 属性,更好的方法是将其添加到“快速设置”中。前往“设置”页面 > “用户界面” > “快速设置列表”。添加CLIP_stop_at_last_layer。点击“应用设置”并“重新加载 UI”。
剪辑跳过滑块应出现在 AUTOMATIC1111 的顶部。
合并两个模型
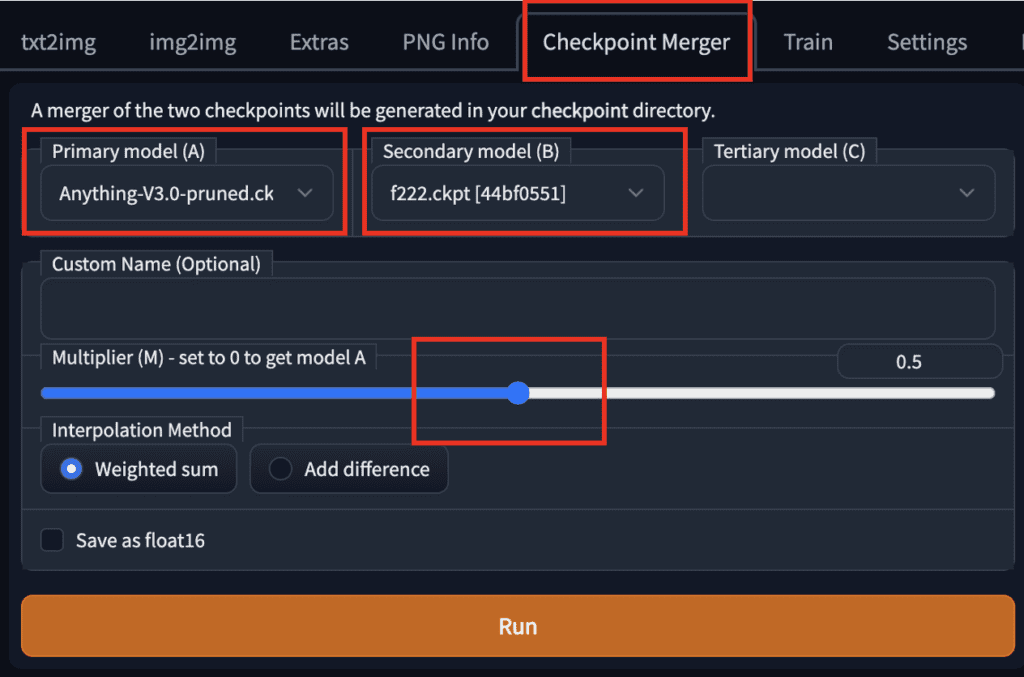
合并两个模型的设置。
要使用 AUTOMATIC1111 GUI 合并两个模型,请转到Checkpoint Merger选项卡,然后在Primary 模型 (A)和Secondary 模型 (B)中选择要合并的两个模型。
调整乘数 (M) 可调整两个模型的相对权重。将其设置为 0.5 会合并两个同等重要性的模型。
按下运行后,新的合并模型将可供使用。
合并模型示例
以下是将F222和Anything V3以相同权重(0.5)合并的示例图像:

比较 F222、Anything V3 和合并版(各占 50%)
合并后的模型介于写实风格的 F222 和动漫风格的 Anything V3 之间。它非常适合用于生成人物插画作品。
稳定扩散模型文件格式
在模型下载页面上,您可能会看到几种模型文件格式。
修剪
满的
仅限 EMA
FP16
FP32
.pt
.safetensor
这让人困惑!你应该下载哪一个?
剪枝模型、完整模型和仅 EMA 模型
一些稳定扩散检查点模型由两组权重组成:(1)最后一个训练步骤后的权重和(2)过去几个训练步骤的平均权重,称为 EMA(指数移动平均值)。
如果您只想使用该模型,可以下载仅包含 EMA 的模型。这些是您使用该模型时使用的权重。它们有时也称为剪枝模型。
如果您想通过额外的训练来微调模型,那么您只需要完整的模型(即由两组权重组成的检查点文件)。
因此,如果您想使用它来生成图像,请下载精简版或仅支持 EMA 的模型。这可以节省一些磁盘空间。相信我,您的硬盘很快就会被占满!
Fp16 和 fp32 模型
FP 代表浮点数。它是计算机存储十进制数的方式。这里的十进制数是模型权重。FP16 每个数占用 16 位,称为半精度。FP32 每个数占用 32 位,称为全精度。
深度学习模型(例如稳定扩散)的训练数据噪声很大。你很少需要全精度模型。额外的精度只会存储噪声!
所以,如果有的话,请下载 FP16 模型。它们大约只有原来的一半大小。这能帮你节省几 GB 的空间!
安全张量模型
原始的 PyTorch 模型格式是.pt。这种格式的缺点是不安全的。有人可能会在其中打包恶意代码。当你使用该模型时,这些代码可能会在你的机器上运行。
Safetensors是 PT 模型格式的改进版本。它的作用与存储权重相同,但不会执行任何代码。
因此,请尽快下载 safetensors 版本。如果没有,请从可靠的来源下载 PT 文件。
其他模型类型
四种主要类型的文件可以称为“模型”。让我们来解释一下,以便您了解人们在谈论什么。
检查点模型是真正的稳定扩散模型。它们包含生成图像所需的所有内容,无需任何额外文件。它们很大,通常为 2 到 7 GB。它们是本文的主题。
文本反转(也称为嵌入)是定义新关键词以生成新对象或样式的小文件。它们很小,通常为 10 到 100 KB。您必须将它们与检查点模型一起使用。
LoRA 模型是用于修改样式的检查点模型的小型补丁文件。它们通常大小为 10-200 MB。您必须将它们与检查点模型一起使用。
概括
我已经介绍了稳定扩散模型、它们的构建方法、一些常用模型以及如何将它们合并。当你心中已经有了特定的风格时,使用模型可以让你的工作更轻松。












Comment